These tasks were developed for research into face and voice recognition ability. The tasks present images of the faces and short clips of the voices of British and American celebrities that were well known to UK participants between the ages of 20-65 during 2019-2020. Different celebrities are presented in the face and voice tasks, and each task presents 30 faces/voices (15 women, 15 men). Celebrities include singers, actors, models, royalty, politicians, athletes, and TV personalities. In addition to the face and voice recognition tasks, there is a task that assesses familiarity with the names of the celebrities presented in the face and voice tasks, and perceived frequency of exposure to their faces and voices. All tasks must be completed on a PC.
The tasks are described in detail in: Tsantani, M., & Cook, R. (2020). Normal recognition of famous voices in developmental prosopagnosia. Scientific reports, 10(1), 1-11.
Built with Task Builder 1
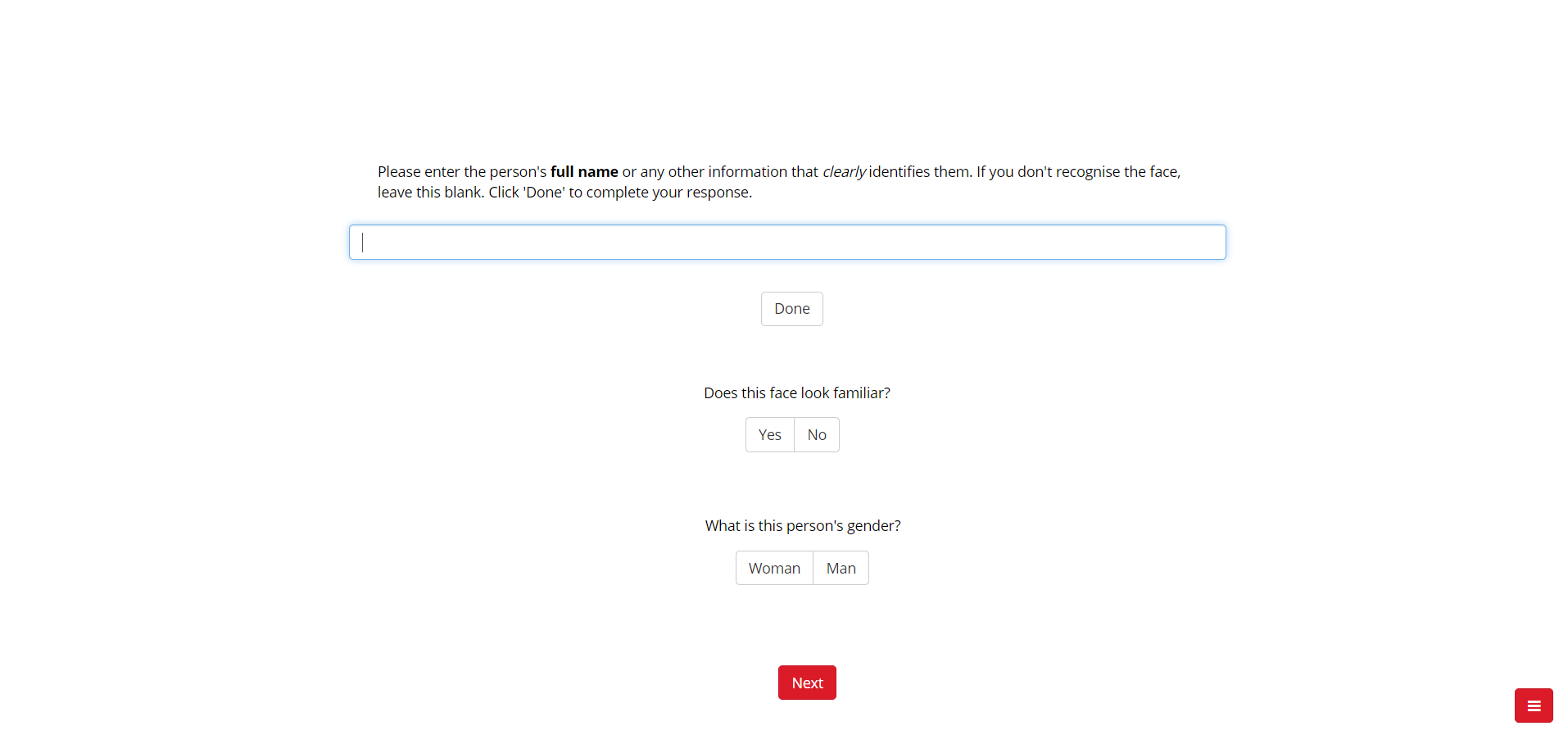
Presents images of the faces of 30 celebrities. Faces are front-facing and exhibit a direct eye gaze and a neutral or smiling facial expression. Faces are cropped to an oval to exclude external features, are in grey-scale and have been equated for luminance.
Each trial begins with a fixation cross presented for 250 ms, followed by a face presented for 5 seconds. In the response screen, participants are asked to identify the person by typing their full name or other uniquely identifying information. They are also asked to determine if the face looks familiar (Yes/No). The presentation order of the stimuli was randomised.
To check that participants are paying attention, there is a question about the gender of each face (Woman/Man).

Gorilla Open Materials Attribution-NonCommerical Research-Only
Built with Task Builder 1
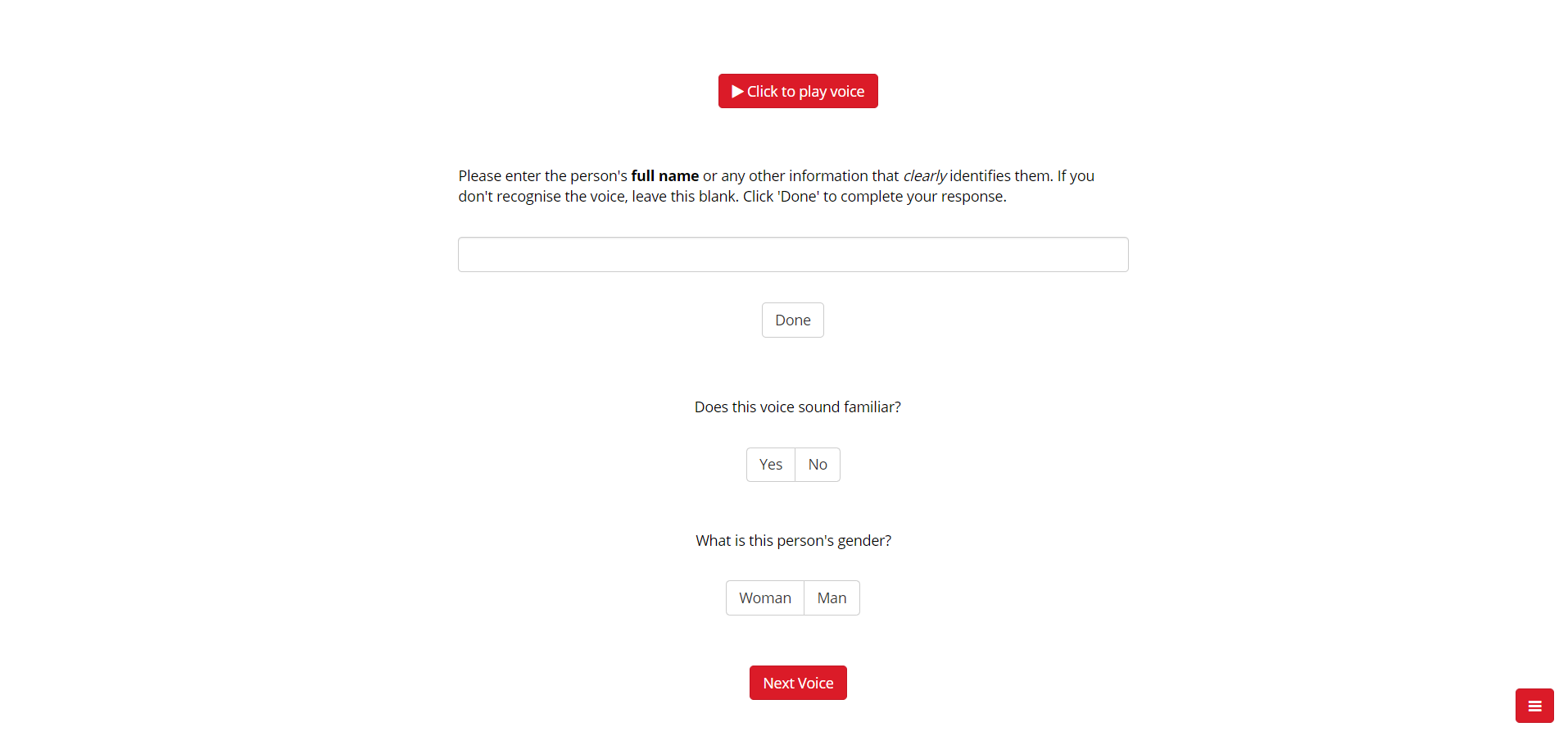
Presents audio clips of the voices of 30 celebrities. The clips contain between 7-10 seconds of speech, and were converted to mono with a sampling rate of 44100, low-pass filtered at 10 KHz, and root-mean-square (RMS) normalised in intensity. The clips were selected so that the speakers could not be identified based on the speech content.
Participants are asked to complete the task in a quiet environment where they can clearly hear sounds from their device, and are encouraged to wear headphones. At the start of the task, participants are presented with an example audio clip which they can replay to adjust the volume on their device to a comfortable level. In each trial, participants are asked to click on a button to hear the audio clip. Each clip can be played up to three times. Participants are then asked to identify the person by typing their full name or other uniquely identifying information. Participants are also asked to report whether the voice sounds familiar (Yes/No). The presentation order of the stimuli is randomised.
Participants are asked whether each speaker was a man or a woman to ensure that they are paying attention.
Gorilla Open Materials Attribution-NonCommerical Research-Only
Built with Task Builder 1
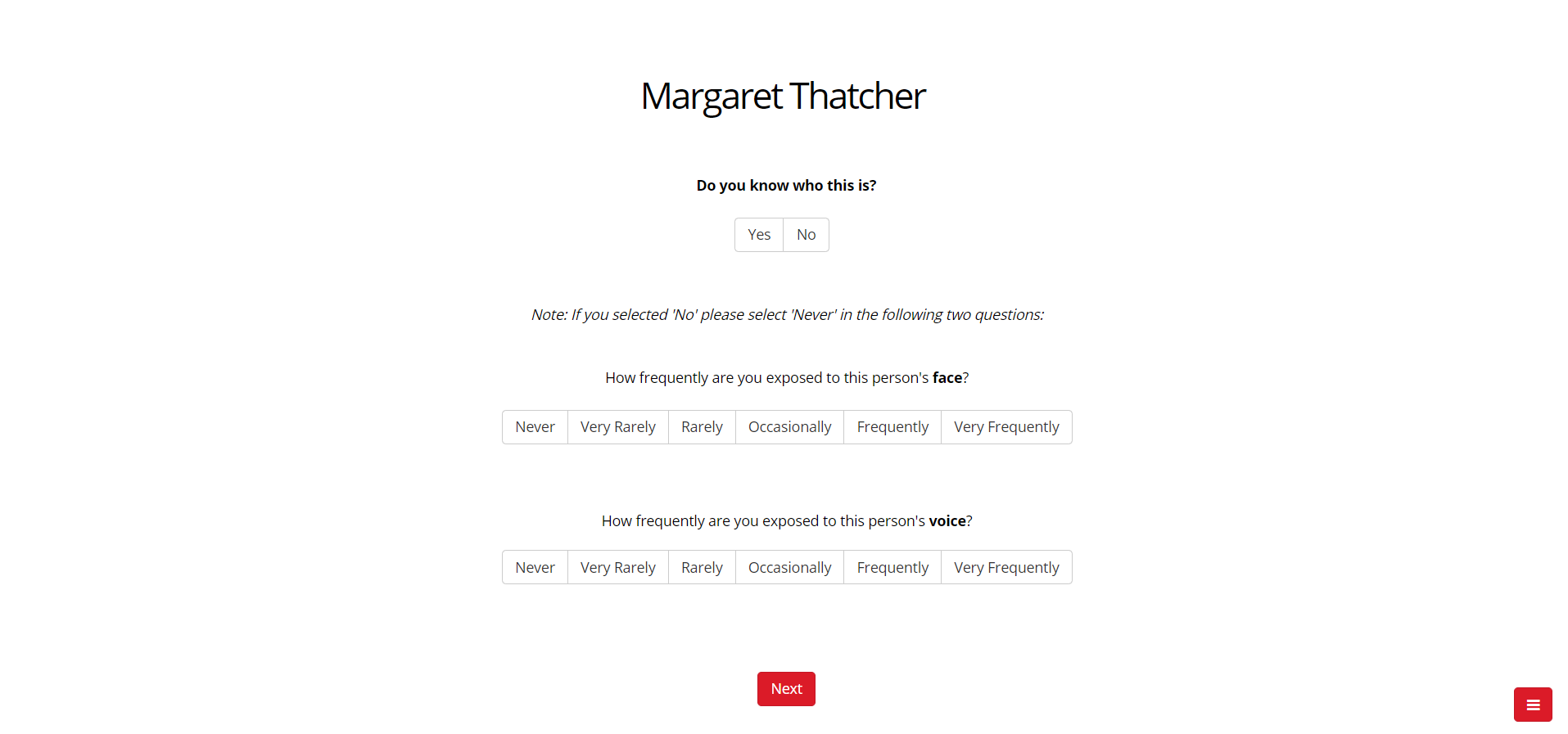
This task should be completed after the famous face and voice recognition tasks. Participants are presented with the names of the sixty celebrities whose face or voice was presented in the face and voice tasks. In each trial, participants view a name, and are asked to indicate whether they know who the person is (Yes/No). They are also asked to indicate how frequently they are exposed to that person’s face or voice using a six-point scale ranging from ‘never’ to ‘very frequently’ (participants are asked to respond ‘never’ if they have indicated that they don’t know the person by name).
Gorilla Open Materials Attribution-NonCommerical Research-Only
Fully open! Access by URL and searchable from the Open Materials search page