This page contains the tasks and questionnaires performed by participants for my dissertation project.
This page is still a work in progress - check back again soon for a detailed description!
Built with Questionnaire Builder 2
I developed the LDQ (Linguistic Diversity Questionnaire) to measure participants' experience with linguistic diversity from their language history, usage, and exposure (hereafter, experiential linguistic diversity). The questionnaire measures overall experiential language diversity through two primary factors: the diversity of known languages (used and studied) and the diversity of regular exposure in a typical week to both known and unknown languages in various situational contexts, such as through media consumption, social environment, and interpersonal connections. I called the former factor "active language use and exposure" (incorporates all four language aspects of speaking, listening, reading, and writing) and the latter factor "passive language use and exposure" (involves only reading or listening but not speaking or writing).
Part 1 of the LDQ, on pages 3-13, measures active language use and exposure. Part 1 of the LDQ, on pages 3-13, is sourced directly from Questions 7, 10, 11, 12, 13, 15, 18, 19, 21, 23, 25, and 27 of the Language History Questionnaire 3 (LHQ 3; P. Li et al., 2020; https://lhq-blclab.org/).
Part 2 of the LDQ, on pages 15-17, measures passive language use and exposure. I developed Part 2 of the LDQ using questions modified from the Language Background Questionnaire (LBQ) used by Yow & Li (2015) and X. Li et al. (2021), the Language Experience and Proficiency Questionnaire (LEAP-Q: Marian et al., 2007 and the survey used by Castro et al. (2022). Part 2 asks participants report hours of language use/exposure for languages they know and don't know in 10 different contexts: four entertainment contexts (watching, listening, games, online), five digital or in-person interpersonal contexts (home, family, social, school/work, out of home), and one unclassified context ("other" specified by the participant if desired).
Responses from the LDQ can be quantitatively scored to produce measures of Multilingual Language Diversity (MLD), a form of language entropy. The MLD score from Part 1, which I call MLD-A (active use and exposure) is calculated using the aggregate scoring equations for the LHQ3. The MLD score from Part 2, which I call MLD-P (passive use and exposure) is calculated using
Note that the LDQ is not automatically scored using the Gorilla scoring function. For more details and the code used to score the LDQ, see the supplementary materials OSF page for my dissertation.
Creative Commons Attribution (CC BY)
Built with Task Builder 2
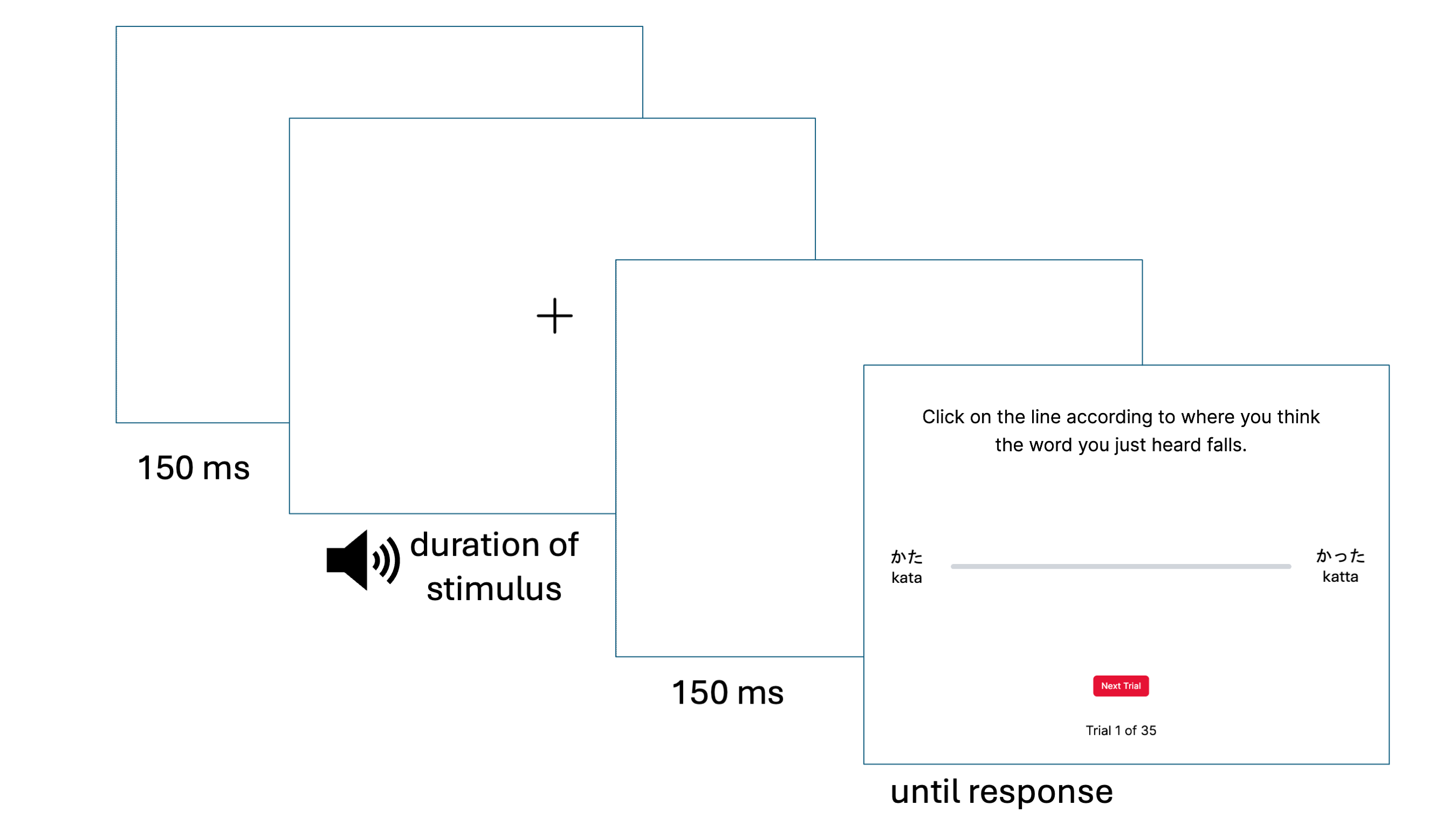
The VAS (Visual Analog Scale) task measures speech categorization gradiency by capturing phonetic judgements along a continuum. The VAS task used across all three studies measures categorization ratings for L1 English and L2 Japanese phonemic contrasts by presenting listeners with tokens along a speech continuum between two spoken words, to which listeners must respond by marking on a line how close they thought the token sounded to one word or the other.
L1 English contrasts used were the stop consonant voicing contrast /d/-/t/ (indent vs. intent) and tense-lax vowel contrast /i/-/ɪ/ (reason vs. risen). L2 Japanese contrasts used were the consonant gemination contrast /t/-/tt/ (kata 'shoulder' vs. katta 'won') and vowel length contrast /o/-/oː/ (toru 'to take' vs. tooru 'to pass through/by'). A bilingual female speaker fluent in both Japanese and English provided the speech recordings for all four pairs.
The Gorilla task contains spreadsheets for two-dimensional continua (7x5 steps along primary acoustic dimension by secondary acoustic dimension for each contrast) and one-dimensional continua (7 steps along primary acoustic dimension at midpoint (step 3) of secondary acoustic dimension). The task also includes instructions for the two-dimensional continua and the pretraining task for the one-dimensional continua.
Trials are blocked by continuum. There are four versions of each the two-dimensional and one-dimensional continua that counterbalances the within-language order of blocks, but the order was always L1 blocks followed by L2 blocks. The left-right position of the words on each endpoint of the scale were randomized for each participant per block using a spreadsheet randomization function.
For the two-dimensional continua (used in Study 1), there are 105 trials per block for a total of 420 trials. Each block is divided into three mini-blocks of 35 trials, with 20-second breaks in between each mini-block and 60-second breaks in between each regular block.
For the one-dimensional continua (used in Studies 2 and 3), there are 28 trials per block for a total of 112 trials with 30-second breaks in between blocks. In Studies 2 and 3, paritcipants completed the VAS task before and after training; the pretraining and posttraining tasks are identical except for the instructions. The posttraining instructions are delivered with a spreadsheet using the "instructions" task.
Creative Commons Attribution (CC BY)
Built with Task Builder 2
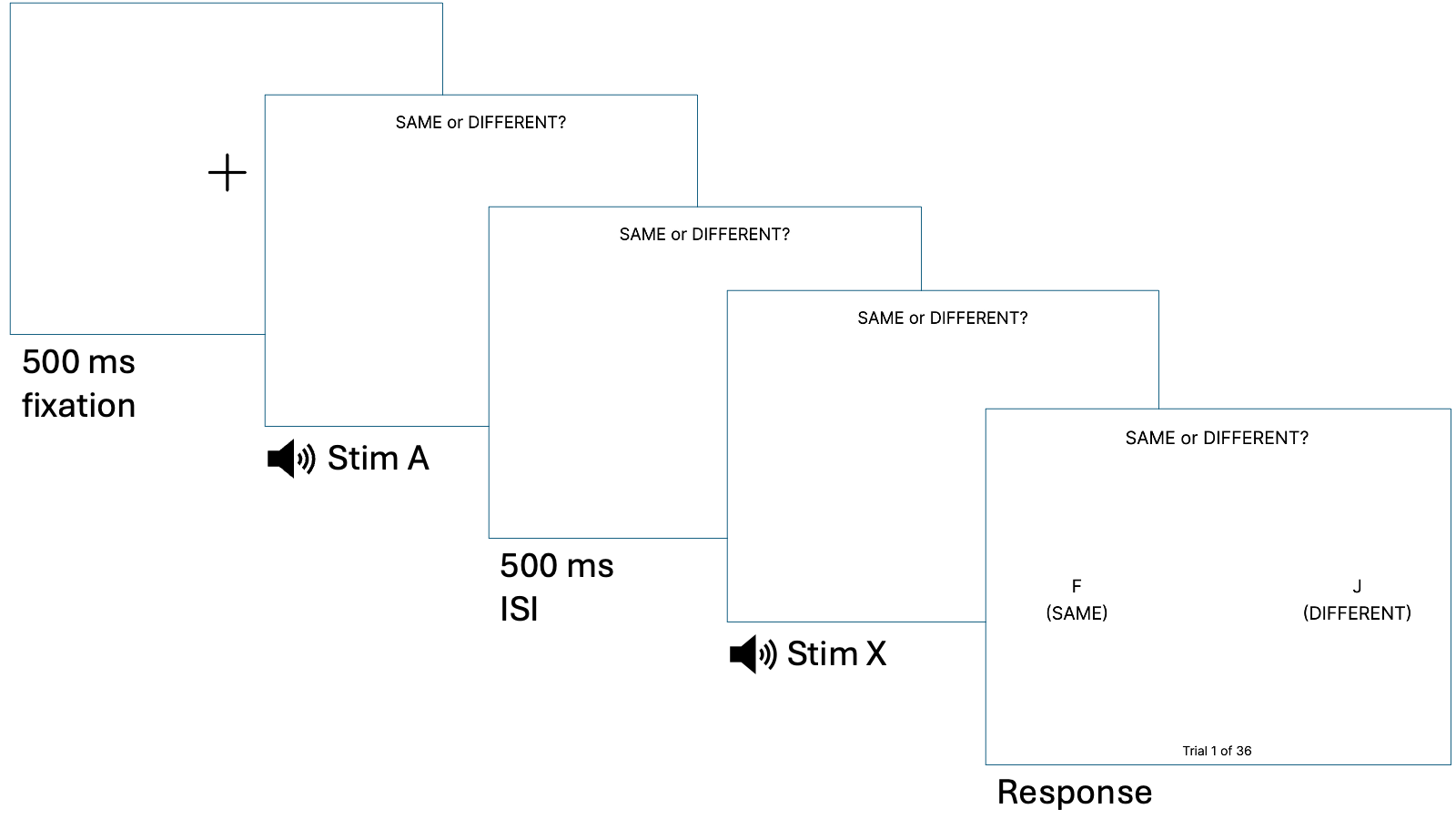
The AX discrimination task, also known as same-different discrimination, measures perceptual discrimination sensitivity in the judgement of two speech tokens as being the same or different. Here, the AX discrimination task is used as both a training paradigm, where participants receive feedback on their answers, and a testing measure, where participants judge novel pairs not heard during training. Participants are trained and tested on the target L2 contrast: Japanese vowel length and consonant gemination. This task was used in Studies 2 and 3.
The novelty of the AX discrimination task used in this dissertation comes from the addition of linguistic diversity as an experimental manipulation. Participants are randomly assigned to one of two conditions for AX discrimination training: Low Linguistic Diversity (Low LD) and High Linguistic Diversity (High LD). Those in the Low LD group train with only Japanese vowel and consonant length minimal pairs, while those in the High LD group train with Japanese and Modern Standard Arabic (MSA) vowel and consonant length minimal pairs. Both groups are tested on novel minimal pairs in Japanese only.
There are 18 Japanese minimal pairs and 18 MSA minimal pairs used for training, and 25 Japanese minimal pairs used for testing. There were an equal number of the four same-different trial types (AA, AB, BA, BB) within the training and testing tasks.
One discrimination training session consists of 288 trials, divided into 8 blocks of 36 trials each with 20-second breaks in between blocks. For the High LD group (using the spreadsheet "training_high_LD"), trials are blocked by language (four blocks of Japanese minimal pairs and four blocks of MSA minimal pairs) and block order is randomized. For the Low LD group (using the spreadsheet "training_low_LD"), Japanese minimal pair trials are repeated to reach the same number of training trials as the High LD group. Participants receive feedback on the correctness of their answer (correct or incorrect) and the trial type (same or different) and have the opportunity to listen to the words presented in the trial, read their orthographic and transliterated transcriptions, and learn their meanings in English.
Participants do not receive feedback during the testing task.
For Study 2, participants underwent one training session. For Study 3, only the experimental groups (Low LD and High LD, but not the Control group) experienced training, and trained for six sessions across several weeks.
For Study 2, both groups took the same pretest and posttest, which were identical except for instructions. There were 100 total trials divided into 4 blocks of 25 trials each, with 15-second breaks in between blocks (using the spreadsheet "testing_all_groups"). For Study 3, all three experimental groups took the same pretest and posttest, which were identical except for instructions, and consisted of 200 total trials divided into 4 blocks of 50 trials each, with 30-second breaks in between blocks (using the spreadsheet "testing_all_groups_long").


Creative Commons Attribution (CC BY)
Built with Task Builder 2
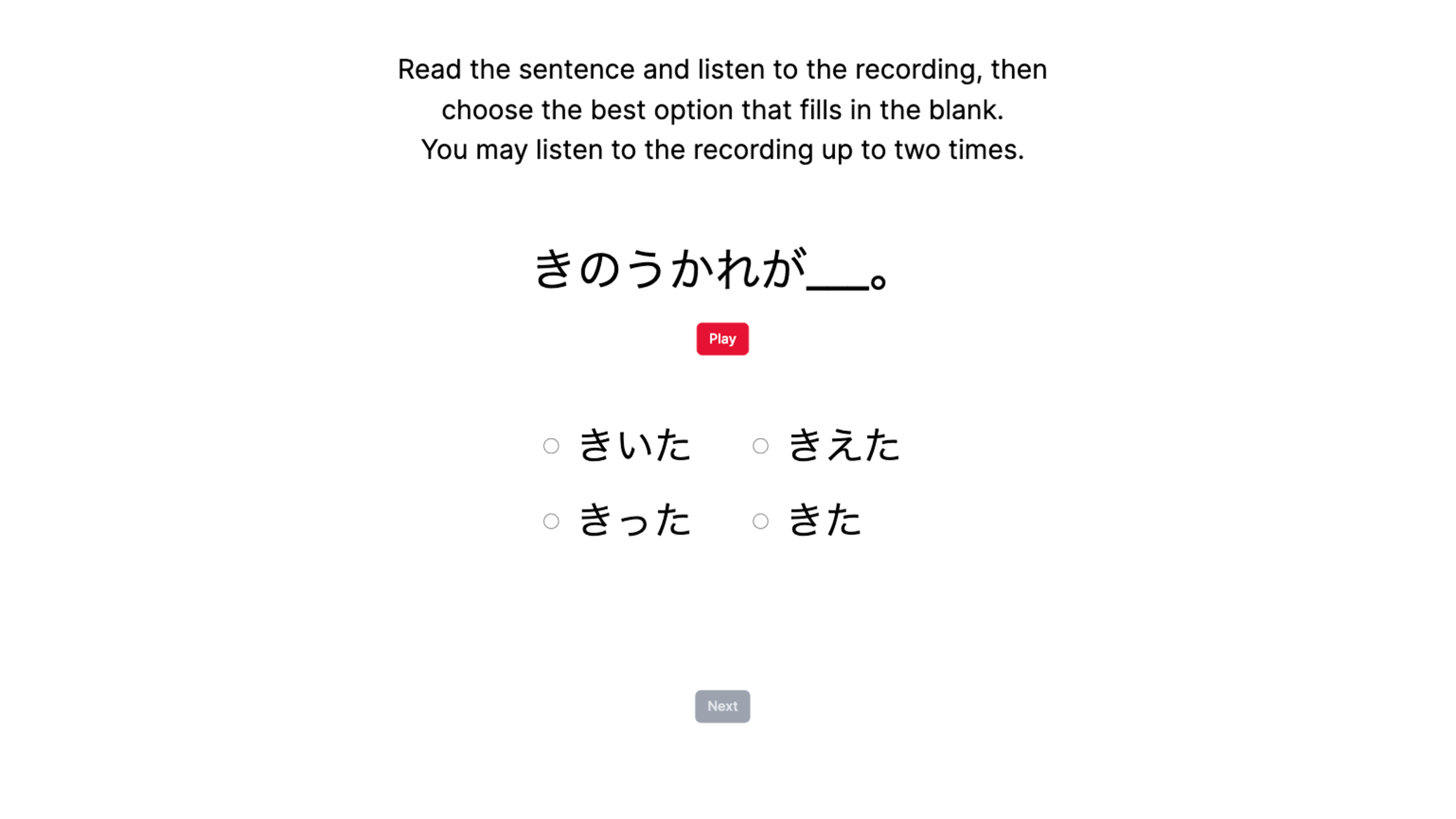
I developed the MCPD (multiple-choice partial dictation) listening assessment task to measure accuracy of L2 listening to natural recordings of Japanese sentences. In each trial, listeners are presented a recording of a sentence while reading a transcript with a word missing. They must choose the most appropriate answer among four choices to fill in the blank.
The idea of the task is that the key word missing from the sentence contains one word of the minimal pairs containing the target contrasts (vowel length and consonant gemination). The other choices include the competing distractor, which is the other half of the minimal pair, and two non-competing distractors, which are either contrastive with the key word according to a non-target phonemic contrast or phonetically/phonologically similar to the key word. The sentences are structurally simple and non-specific in content to enable any of the answer options to fit in the blank space both semantically and syntactically in Japanese.
There are 20 total trials in the task, and listeners do not receive feedback. The key words include 10 words used in the AX discrimination training task and 10 words used in AX discrimination testing task, and are equally distributed between vowel and consonant target phonemes. The same female speaker as the VAS task provided the speech recordings for all sentences.
This task was used only in Study 3 and was performed by all three experimental groups (Control, Low LD, High LD). The task contains separate spreadsheets for prettest and posttest, which are identical but differentiated by the instructions display.
Creative Commons Attribution (CC BY)
Built with Task Builder 2
Instructions for various tasks, depending on condition and time point (pretest/posttest/training session).
Includes displays/spreadsheets giving instructions for the following task specifications:
For Study 2:
For Study 3:
Creative Commons Attribution (CC BY)
Built with Questionnaire Builder 2
IRB-approved consent from for Study 1. Approved for recruitment from Prolific.com only.
Creative Commons Attribution (CC BY)
Built with Experiment
Experiment tree for Study 1.
The purpose of Study 1 was to measure the degree to which experiential linguistic diversity, measured using the LDQ, predicted degree of categorization gradiency and secondary cue use for L1 English and L2 Japanese contrast pairs, using the VAS task with two-dimensional speech continua.
Experiment steps:
Set up:
Study tasks:
Study 1 was a one day study that took an hour or less to complete. The autoplay and headphone check were cloned from the open materials Gorilla page from Milne et al., 2021.
Creative Commons Attribution (CC BY)
Built with Questionnaire Builder 2
IRB-approved consent from for Study 2. Approved for recruitment from Prolific.com only.
Creative Commons Attribution (CC BY)
Built with Experiment
Experiment tree for Study 2.
Creative Commons Attribution (CC BY)
Built with Questionnaire Builder 2
IRB-approved consent form for Study 3 Control group. Approved for recruitment via language classrooms visits and email only. Approved by Carnegie Mellon University IRB.
Creative Commons Attribution (CC BY)
Built with Experiment
Creative Commons Attribution (CC BY)
Built with Questionnaire Builder 2
IRB-approved consent form for Study 3 Low LD and High LD experimental groups. Approved for recruitment via language classrooms visits and email only. Approved by Carnegie Mellon University IRB.
Creative Commons Attribution (CC BY)
Built with Experiment
Creative Commons Attribution (CC BY)
Built with Experiment
Fully open! Access by URL and searchable from the Open Materials search page